3年半ほど前にデジタル一眼カメラを買ってから1年に1万枚以上撮っているわけですが、実は写真の撮り方とかはほとんど勉強してこなかったので、やっと参考書を読むようになりました(個人的にはとりあえずやってみるよりも体系的な学習のほうがよく身に着くタイプなのですが…)。そんな中、ニュース巡回中にこの記事が目に留まりました。
実例を交えたテクニックが豊富に載っているので、とりあえず無料のうちに読んでおこうと思いました。
インプレス (2015-04-17)
売り上げランキング: 10,405
公開が終わり次第電子書籍も買ったのですが、無料公開しているものもローカルに保存しようと思い試行錯誤したのでその方法をメモしておきます。なお、この記事は無料公開期間の終了後に公開しています。
期間限定で無料公開されていた「イラストでよくわかる 写真家65人のレンズテクニック」のURLはこちらです(現在は閲覧できません)。
小学館による tameshiyo.me のサブドメインで、他にも複数の出版社が試し読み版を公開していますので、この手法は tameshiyo.me ドメインの他のコンテンツにも使えます。
何はともあれ開発者ツールを開き、画像を表示しているDOM要素を探します。「イラストでよくわかる 写真家65人のレンズテクニック」が公開終了してしまったので、説明用に別のコンテンツで見てみます。
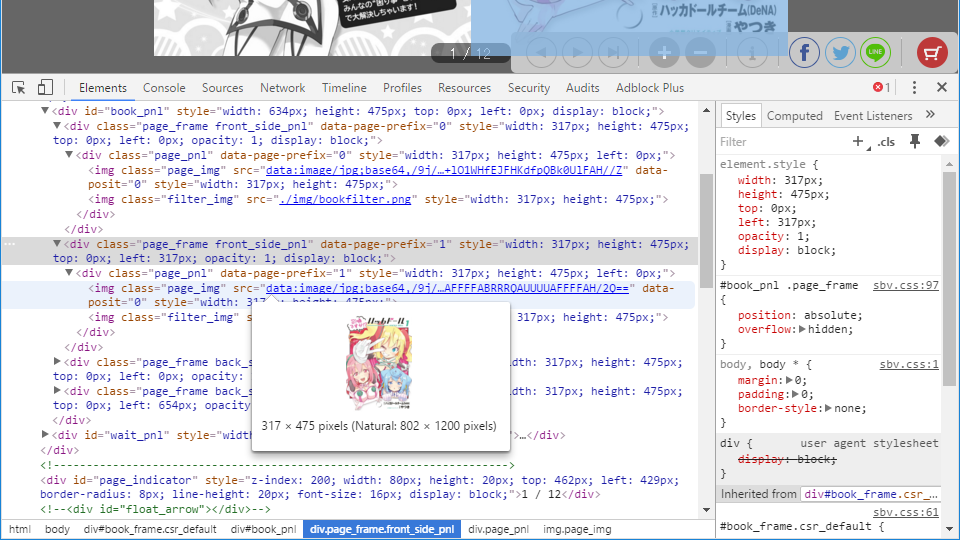
表示されている画像はDOMツリーとしては html > body > div#book_frame > div#book_pnl > div.page_frame > div.page.pni > img.page_img の要素にあります。div.page_frame要素の独自データ属性data-page-prefixは0から3まで4つあり、ページをめくると0と1、2と3の組み合わせで中のimg要素が切り替わります。
img要素のsrc属性には画像ファイルのURLではなく、data URIスキームで画像データが直接入っています。data URIはdata:image/jpeg;base64,0123...という書式で、0123...の部分にBASE64エンコードされたデータが入っています。これをBASE64デコードしてファイルに書き出せばよいわけです。画像形式はimage/jpegの通りJPEGです。例外として空白ページはサーバ上のPNG画像のURLが入ります。
肝心の画像データはコンテンツのURL読み込み時にサーバより取得しているようですが、WebアプリテストライブラリであるGebを使って通常のブラウザを操作し、人間が使用しているのと同じ方法でアクセスを行いつつ取得をしてみます。
コードはこちら。先にGistに書いていたものです。Gebなので言語はGroovyです。
@Grab('org.gebish:geb-core')
@Grab('org.seleniumhq.selenium:selenium-firefox-driver')
@GrabExclude('org.codehaus.groovy:groovy-all')
import geb.Browser
Browser.drive {
go 'http://impress.tameshiyo.me/9784844337966'
sleep(2000)
// get encoded iamges in data URI
def list = []
// 89 pages
(0..88).each { page ->
list << $('div.page_pnl', 'data-page-prefix': "${page % 2 * 2}")?.children()[0].@src
list << $('div.page_pnl', 'data-page-prefix': "${page % 2 * 2 + 1}")?.children()[0].@src
$('div#book_frame').click()
sleep(1000)
}
// decode & save iamges
list.eachWithIndex { url, index ->
if(url.startsWith('data:') && url.split(',').size() == 2) {
def data = url.split(',')[1]
new File("page${index}.jpg").bytes = Base64.getDecoder().decode(data)
}
}
}
簡単なコード解説:go URLで目的のページにアクセスします。listへ目的のsrc属性の内容を追加しつつ、ページの要素をクリックして次のページに移動します。これを必要なページ数だけ行った後にlistからdata URIのデータ部分を抜き出して(この部分はfindAllでdata URIをフィルタしたり、collectでデータ部分を抜き出すするなど、よりGroovyらしくも書けます)、あとはBase64でデコードしたデータをファイルに書き出します。
実行した動画はこちら。Firefoxが起動してページをめくっていきます。最後のページまでめくるとカレントディレクトリにページのJPEGファイルが出力されます。
あとはそのまま画像ビューアで閲覧したり、PDF化してOCRしたり自由に扱えます。
最後にお約束:この方法に限らず、Webから入手したコンテンツは著作権法および利用条件の下で正しく活用してくださいね。


コメントする